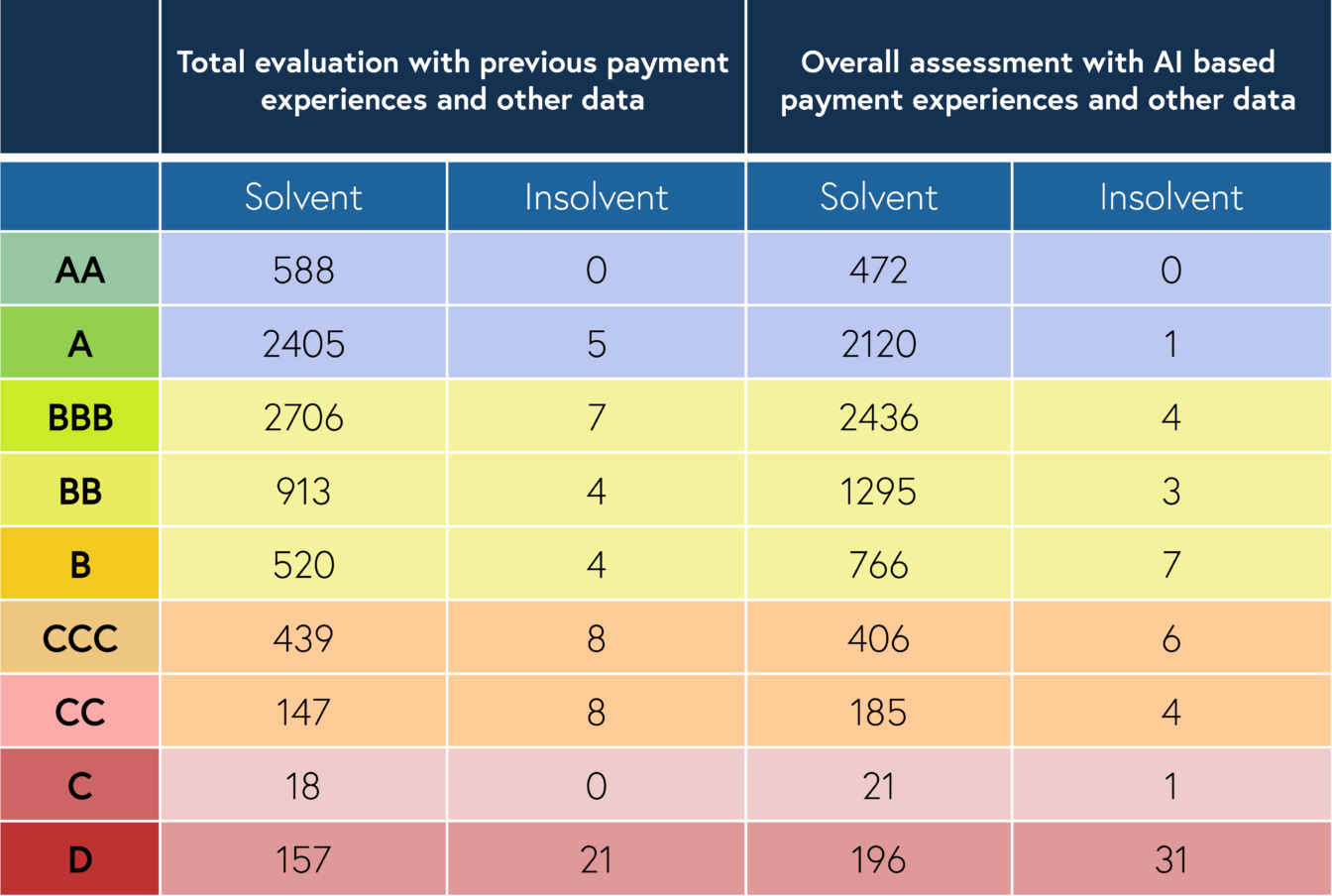
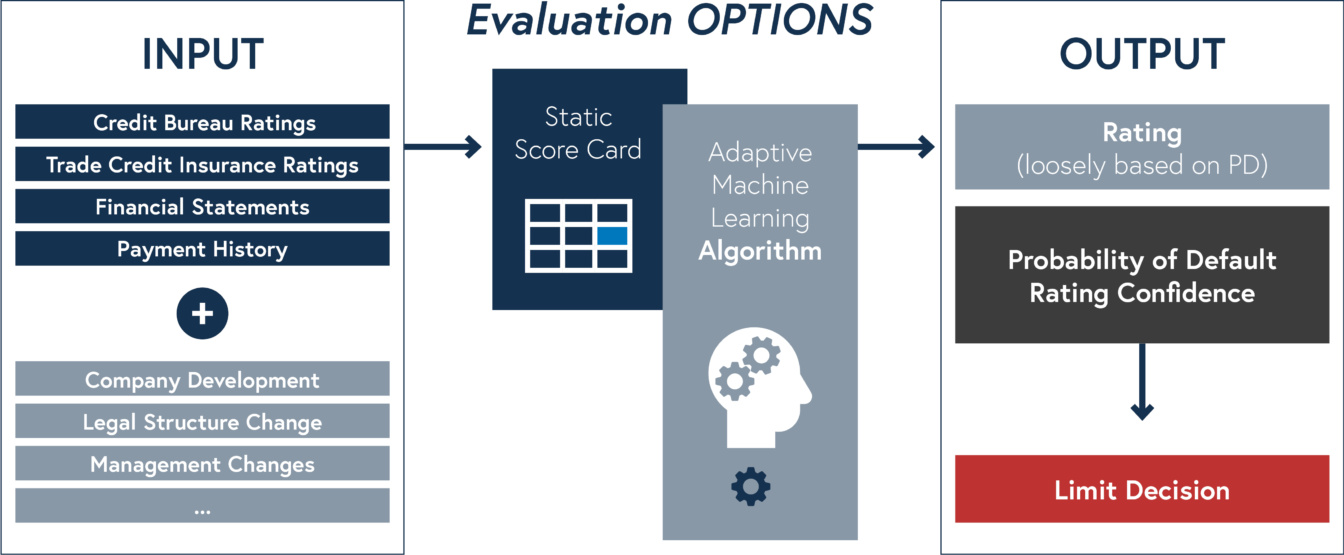
If these requirements are met, we offer the ability to support different business use cases based on three different models. At this point, it is important not to underestimate the amount of research and development that goes into data validation, quality assurance and other requirements that directly affect the performance of a model. It is important to define how irrelevant or inconsistent data will be handled and what individual adjustments will need to be made to the data model. This requires coordination at both business and technical levels to jointly eliminate unwanted side effects and achieve a robust prediction.
We have developed three different models that allow us to further optimise our customers' receivables management. Based on a debtor's historical payment behaviour, we have succeeded in developing a model that is able to predict very accurately the deviation of a payment from the due date. This enables not only risk assessment of individual documents, but also modelling of a company's liquidity. We have developed a wide range of processes to ensure the above aspects of data quality assurance and, in this respect, model forecasting, which also enables us to develop client-specific models.
We also analysed payment patterns to classify debtor behaviour over time and to identify changes. In this context, we developed a model that classifies debtors at time x (specified by the receipt of a payment) using a clustering approach. From the technical task, we were able to derive a functional definition of the clusters found, which allows us to distinguish between early, late, discount and on-time payers, as well as to identify unstructured payers. The advantage of this analysis is that it is possible to better assess the development of an individual debtor, as well as changes in the clusters of the entire debtor portfolio over time.